Анализ трендов в Твиттере с использованием Python

В этой статье мы изучим процесс сбора данных в Twitter, обработки текста и географического отображения данных. Мы будем иметь дело с подмножеством данных, имеющим ключевые слова #python и #javascript.
Сбор данных
При сборе данных мы ограничены двумя способами.
1. Невозможно собрать данные из прошлого (год назад и т.д.)
2. Twitter бесплатно предоставляет выборку своих данных (например 1%).
Тем не менее, 1% данных составляет порядка нескольких миллионов твитов в день. Многие компании, работающие в социальных сетях, имеют API, которые доступны сторонним разработчикам и исследователям. Твиттер имеет много доступных API.
Согласно документам, потоковый API Twitter используется для загрузки сообщений в режиме реального времени. Это полезно для получения большого количества твитов или для создания прямой трансляции с использованием потока сайта или потока пользователя. Он имеет две конечные точки фильтра и выборки. С помощью конечной точки фильтра пользователи могут запрашивать данные, используя несколько сотен ключевых слов, несколько тысяч имен пользователей и 25 диапазонов местоположений. В примере конечной точки, твиттер будет возвращать 1% всех твитов. Для сбора данных из Streaming API мы будем использовать пакет под названием tweepy, который абстрагирует работу по настройке стабильного соединения Streaming API. Нам нужно иметь собственную учетную запись Twitter и ключи API для аутентификации.
from tweepy import OAuthHandler
from tweepy import API
# Consumer key authentication(consumer_key,consumer_secret can be collected from our twitter developer profile)
auth = OAuthHandler(consumer_key, consumer_secret)
# Access key authentication(access_token,access_token_secret can be collected from our twitter developer profile)
auth.set_access_token(access_token, access_token_secret)
# Set up the API with the authentication handler
api = API(auth)
tweepy требует объект под названием SListener, который говорит ему, как обрабатывать входящие данные. Объект SListener открывает новый файл метки времени для хранения твитов и принимает необязательный аргумент API. Приведенный ниже код будет работать до тех пор, пока не будет остановлен явно (чем больше время выполнения, тем больше количество объектов JSON в нашем файле). Набор данных в этой статье состоит из 685 твитов (объектов Twitter JSON), которые были получены в короткий промежуток с 19:39 до 19:44.
from tweepy import Stream
# Set up words to track
keywords_to_track = ['#javascript','#python']
# Instantiate the SListener object
listen = SListener(api)
# Instantiate the Stream object
stream = Stream(auth, listen)
# Begin collecting data
stream.filter(track = keywords_to_track)
Теперь файл с именем tweets.json будет содержать объекты JSON. Количество объектов JSON зависит от открытия и закрытия вышеуказанного соединения.
Обработка Twitter JSON
Формат данных json - это специальный формат данных, который читается человеком и легко передается между компьютерами. Это комбинация словарей и списков. Каждый объект JSON имеет много дочерних объектов. В нашем случае каждый объект JSON описывает твит, favourites_count, retweet_count и т.д. и имеет вложенные словари, которые описывают пользователя, местоположение и т.д.

Обработка данных
Чтобы анализировать твиты в масштабе, лучше хранить эти твиты в кадре данных Pandas. Это позволяет нам применять методы анализа к строкам и столбцам. Однако с вложенными словарями объект JSON является сложным. Чтобы преодолеть эту проблему, мы сплющим объект JSON (сохраняем все атрибуты на одном уровне, а не во вложении).

tweets = []
files = list(glob.iglob('/content/tweets.json'))
for f in files:
fh = open(f, 'r', encoding = 'utf-8')
tweets_json = fh.read().split("\n")
## remove empty lines
tweets_json = list(filter(len, tweets_json))
## parse each tweet
for tweet in tweets_json:
tweet_obj = json.loads(tweet)
# Store the user screen name in 'user-screen_name'
tweet_obj['user-screen_name'] = tweet_obj['user']['screen_name']
# Check if this is a 140+ character tweet
if 'extended_tweet' in tweet_obj:
# Store the extended tweet text in 'extended_tweet-full_text'
tweet_obj['extended_tweet-full_text'] = tweet_obj['extended_tweet']['full_text']
if 'retweeted_status' in tweet_obj:
# Store the retweet user screen name in 'retweeted_status-user-screen_name'
tweet_obj['retweeted_status-user-screen_name'] = tweet_obj['retweeted_status']['user']['screen_name']
# Store the retweet text in 'retweeted_status-text'
tweet_obj['retweeted_status-text'] = tweet_obj['retweeted_status']['text']
if 'quoted_status' in tweet_obj:
# Store the retweet user screen name in 'retweeted_status-user-screen_name'
tweet_obj['quoted_status-user-screen_name'] = tweet_obj['quoted_status']['user']['screen_name']
# Store the retweet text in 'retweeted_status-text'
tweet_obj['quoted_status-text'] = tweet_obj['quoted_status']['text']
tweets.append(tweet_obj)
Давайте загрузим список твитов в DataFrame.
df_tweet = pd.DataFrame(tweets)
Теперь давайте сравним количество твитов, имеющих теги #python и #javascript. Давайте напишем функцию, которая будет проверять наличие данного хэштега во всех текстовых столбцах и возвращать серию логических значений, указывающих, имеет ли каждая строка это ключевое слово или нет.
def check_word_in_tweet(word, data):
"""Checks if a word is in a Twitter dataset's text.
Checks text and extended tweet (140+ character tweets) for tweets,
retweets and quoted tweets.
Returns a logical pandas Series.
"""
contains_column = data['text'].str.contains(word, case = False)
contains_column |= data['extended_tweet-full_text'].str.contains(word, case = False)
contains_column |= data['quoted_status-text'].str.contains(word, case = False)
contains_column |= data['retweeted_status-text'].str.contains(word, case = False)
return contains_column
# Find mentions of #python in all text fields
python = check_word_in_tweet('python', df_tweet)
# Find mentions of #javascript in all text fields
js = check_word_in_tweet('javascript', df_tweet)
# Print proportion of tweets mentioning #python
print("Proportion of #python tweets:", np.sum(python) / df_tweet.shape[0])
# Print proportion of tweets mentioning #rstats
print("Proportion of #javascript tweets:", np.sum(js) / df_tweet.shape[0])
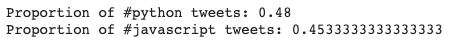
Мы можем заметить, что #python немного опережает #javascript. Теперь давайте попробуем понять, как упоминаются вышеупомянутые два ключевых слова с течением времени. Твиты о продуктах, компании сильно различаются по времени. Давайте попробуем уловить изменение во времени. Когда данные помечены датой и временем, они известны как данные временного ряда.
Во-первых, давайте преобразуем столбец created_at в тип DateTime. Нам нужно создать метрику, которая может быть построена с течением времени. Давайте создадим два столбца python и js который состоит из логических значений.
# Print created_at to see the original format of datetime in Twitter data
print(df_tweet['created_at'].head())
# Convert the created_at column to np.datetime object
df_tweet['created_at'] = pd.to_datetime(df_tweet['created_at'])
# Print created_at to see new format
print(df_tweet['created_at'].head())
# Set the index of df_tweet to created_at
df_tweet = df_tweet.set_index('created_at')
# Create a python column
df_tweet['python'] = check_word_in_tweet('python', df_tweet)
# Create an js column
df_tweet['js'] = check_word_in_tweet('javascript', df_tweet)
Теперь давайте создадим в среднем за минуту упоминания обоих хэштегов и построим их по времени. Мы будем использовать метод Series resample(), который позволит нам суммировать данные за выбранный промежуток времени и применять к нему агрегатную функцию.
import matplotlib.pyplot as plt
# Average of python column by day
mean_python = df_tweet['python'].resample('1 min').mean()
# Average of js column by day
mean_js = df_tweet['js'].resample('1 min').mean()
# Plot mean python/js by day
plt.plot(mean_python.index.minute, mean_python, color = 'green')
plt.plot(mean_js.index.minute, mean_js, color = 'blue')
# Add labels and show
plt.xlabel('Minute'); plt.ylabel('Frequency')
plt.title('Language mentions over time')
plt.legend(('#python', '#js'))
plt.show()
resample(“1 min”).mean() будет группировать данные по минутам и применять среднюю функцию к сгруппированным данным.
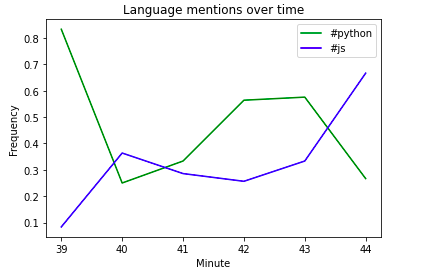
Как я уже упоминал, мы получили данные с 19:39 до 19:44. Мы можем заметить, что минутная ось имеет значения от 39 до 44, и мы можем заметить, как частота изменяется во времени.
Анализ настроений
Анализ настроений - это метод извлечения значения из текста. Это тип метода обработки естественного языка, который определяет, является ли слово, предложение, абзац, документ положительным или отрицательным. Каждый документ получает положительную или отрицательную оценку в зависимости от количества положительных и отрицательных слов. Это может быть использовано для анализа реакций на продукт, компанию и т.д.
Мы будем использовать VADER SentimentIntensityAnalyzer, включенный в набор инструментов для естественного языка, или nltk. Это полезно для анализа коротких документов, особенно твитов. Учитывает смайлики и заглавные буквы тоже.
Каждая оценка настроений от VADER Analyzer содержит 4 значения. Отрицательный, положительный, нейтральный и сложный. Первые 3 говорят сами за себя и находятся в диапазоне от 0 до 1, тогда как составное значение находится в диапазоне от -1 до 1. Ближе к 1 означает положительное значение, а -1 означает отрицательное значение. Мы снова пересмотрим данные по минутам и найдем оценки настроений за каждую минуту.
# Load SentimentIntensityAnalyzer
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# Instantiate new SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
# Generate sentiment scores
sentiment_scores = df_tweet['text'].apply(sid.polarity_scores)
# Print out the text of a positive tweet
print(df_tweet[sentiment > 0.6]['text'].values[0])
# Print out the text of a negative tweet
print(df_tweet[sentiment < -0.6]['text'].values[0])
# Generate average sentiment scores for #python
sentiment_py = sentiment[ check_word_in_tweet('#python', df_tweet) ].resample('1 min').mean()
# Generate average sentiment scores for #javasrcipt
sentiment_js = sentiment[ check_word_in_tweet('#javascript', df_tweet) ].resample('1 min').mean()
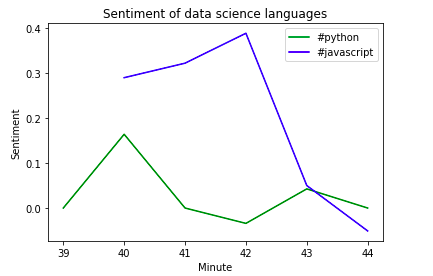
Мы можем заметить, что в небольшом подмножестве данных, которые у нас есть, нет отрицательных твитов, тогда как у javascript больше положительных твитов по сравнению с питоном.
Мы можем выбирать данные по дням, месяцам в зависимости от собираемых нами данных и проводить аналогичные анализы, чтобы получить больше информации.
Полный код можно найти здесь.