Celery Python: основы и примеры

Все в сообществе Python слышали о Celery хотя бы один раз, и, возможно, уже работали с ним. По сути, это удобный инструмент, который помогает запускать отложенный или выделенный код в отдельном процессе или даже на отдельном компьютере или сервере. Это экономит время и усилия на многих уровнях.
Введение в Celery Python
Celery снижает нагрузку на производительность, выполняя часть функциональности в виде отложенных задач либо на том же сервере, что и другие задачи, либо на другом сервере. Чаще всего разработчики используют его для отправки электронных писем. Тем не менее, Celery может предложить гораздо больше. В этой статье я покажу вам некоторые основы Celery, а также пару лучших практик Python-Celery.
Основы Celery
Если вы уже работали с Celery, не стесняйтесь пропустить эту главу. Но если в Celery вы новичок, здесь вы узнаете, как включить Celery в своем проекте, и примите участие в отдельном руководстве по использованию Celery с Django. По сути, вам нужно создать экземпляр Celery и использовать его для пометки функций Python как задач.
Лучше создать экземпляр в отдельном файле, так как будет необходимо запустить Celery так же, как он работает с WSGI в Django. Например, если вы создадите два экземпляра Flask и Celery в одном файле в приложении Flask и запустите его, у вас будет два экземпляра, но вы будете использовать только один. То же самое, когда вы запускаете Celery.
Основные примеры Python Celery
Как я упоминал ранее, в случае использования Celery отправляется электронное письмо. Я буду использовать этот пример, чтобы показать вам основы использования Celery. Вот краткое руководство по Celery Python:
from django.conf import settings
from django.core.mail import send_mail
from django.template import Engine, Context
from myproject.celery import app
def render_template(template, context):
engine = Engine.get_default()
tmpl = engine.get_template(template)
return tmpl.render(Context(context))
@app.task
def send_mail_task(recipients, subject, template, context):
send_mail(
subject=subject,
message=render_template(f'{template}.txt', context),
from_email=settings.DEFAULT_FROM_EMAIL,
recipient_list=recipients,
fail_silently=False,
html_message=render_template(f'{template}.html', context)
)В этом коде используется Django, поскольку он является нашей основной средой для веб-приложений. Используя Celery, мы сокращаем время ответа клиенту, поскольку отделяем процесс отправки от основного кода, отвечающего за возврат ответа.
Самый простой способ выполнить эту задачу - вызвать метод delay, у функции с декоратором app.task.
send_mail_task.delay(('noreply@example.com', ), 'Celery cookbook test', 'test', {})Не только это - Celery дает больше преимуществ. Например, мы можем настроить повторные попытки после сбоя.
@celery_app.task(bind=True, default_retry_delay=10 * 60)
def send_mail_task(self, recipients, subject, template, context):
message = render_template(f'{template}.txt', context)
html_message = render_template(f'{template}.html', context)
try:
send_mail(
subject=subject,
message=message,
from_email=settings.DEFAULT_FROM_EMAIL,
recipient_list=recipients,
fail_silently=False,
html_message=html_message
)
except smtplib.SMTPException as ex:
self.retry(exc=ex)Теперь задача будет перезапущена через десять минут, если отправка не удалась. Кроме того, вы сможете установить количество повторных попыток.
Некоторые из вас могут удивиться, почему я переместил шаблон рендеринга за пределы send_mail call. Это потому, что мы заключаем вызов send_mail в try/except, и лучше иметь как можно меньше кода внутри этого блока.
Django Celery - запланированные задачи
Celery позволяет запускать задачи с помощью планировщиков, таких как crontab в Linux.
Прежде всего, если вы хотите использовать периодические задачи, вы должны запустить воркер Celery с флагом -beat, иначе Celery будет игнорировать планировщик. Следующим шагом будет создание конфигурации, в которой будет указано, какую задачу следует выполнить и когда. Вот пример:
from celery.schedules import crontab
CELERY_BEAT_SCHEDULE = {
'monday-statistics-email': {
'task': 'myproject.apps.statistics.tasks.monday_email',
'schedule': crontab(day_of_week=1, hour=7),
},
}если вы не используете Django, вы должны использовать
celery_app.conf.beat_scheduleвместоCELERY_BEAT_SCHEDULE
В этой конфигурации есть только одна задача, которая будет выполняться каждый понедельник в 7 часов утра. Корневой ключ (monday-statistics-email) - это имя или cronjob, а не задача.
Вы можете добавить аргументы к задачам и выбрать, что нужно сделать, если одна и та же задача должна выполняться в разное время с разными аргументами. Метод crontab поддерживает синтаксис системы кронтаба - такой, как crontab(minute=’*/15’) - для запуска задачи каждых 15 минут.
Отложенное выполнение задачи в Celery
Вы также можете установить Python Celery задачи в очереди с тайм-аутом перед выполнением. (Например, когда вам нужно отправить уведомление после действия.) Для этого используйте аргумент apply_async method с eta или countdown.
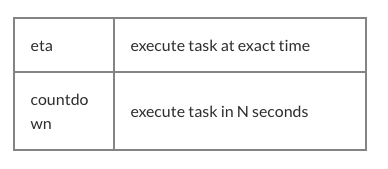
Давайте посмотрим, как это может выглядеть в коде:
from datetime import datetime
send_mail_task.apply_async(
(('noreply@example.com', ), 'Celery cookbook test', 'test', {}),
countdown=15 * 60
)
send_mail_task.apply_async(
(('noreply@example.com', ), 'Celery cookbook test', 'test', {}),
eta=datetime(2019, 5, 20, 7, 0)В первом примере электронное письмо будет отправлено через 15 минут, а во втором - в 7 часов утра 20 мая.
Настройка Python Celery Queues
Celery может быть распределен, когда у вас есть несколько воркеров на разных серверах, которые используют одну очередь сообщений для планирования задач. Вы можете настроить дополнительную очередь для вашей задачи / воркера. Например, отправка электронных писем является важной частью вашей системы, и вы не хотите, чтобы какие-либо другие задачи влияли на отправку. Затем вы можете добавить новую очередь, назовем ее mail и использовать эту очередь для отправки электронных писем.
CELERY_TASK_ROUTES = {
'myproject.apps.mail.tasks.send_mail_task': {'queue': 'mail', },
}если вы не используете Django, используйте
celery_app.conf.task_routesвместоCELERY_TASK_ROUTES
Запустите два отдельных воркера Celery для очереди по умолчанию и новой очереди:
celery -A myproject worker -l info -Q celery celery -A myproject worker -l info -Q mail
В первой строке будет запущен воркер для очереди celery по умолчанию, а во второй - воркер для очереди mail. Вы можете использовать первый воркер без аргумента -Q, тогда он будет использовать все настроенные очереди.
Долгосрочные задачи Python Celery
Иногда мне приходится иметь дело с заданиями, написанными для просмотра записей в базе данных и выполнения некоторых операций. Довольно часто разработчики забывают о росте данных, что может привести к очень длительному времени выполнения задачи. Всегда лучше писать такие задачи, которые позволяют работать с блоками данных. Самый простой способ - добавить смещение и ограничить параметры задачи. Это позволит вам указать размер фрагмента и курсор для получения нового фрагмента данных.
@celery_app.task
def send_good_morning_mail_task(offset=0, limit=100):
users = User.objects.filter(is_active=True).order_by('id')[offset:offset + limit]
for user in users:
send_good_morning_mail(user)
if len(users) >= limit:
send_good_morning_mail_task.delay(offset + limit, limit)Это очень простой пример того, как такая задача может быть реализована. В конце задачи мы проверяем, сколько пользователей мы нашли в базе данных. Если число равно пределу, то, вероятно, у нас есть новые пользователи для обработки. Поэтому мы снова запускаем задачу с новым смещением. Если количество пользователей меньше лимита, это означает, что это последний кусок, и нам не нужно продолжать. Но будьте осторожны: для реализации этой задачи каждый раз должен быть одинаковый порядок записей.
Celery: получение результатов задачи
Большинство разработчиков не записывают результаты, полученные после выполнения задачи. Представьте, что вы можете взять часть кода, назначить его для задачи и выполнить эту задачу независимо, как только вы получите запрос пользователя. Когда нам нужны результаты задания, мы либо сразу получаем результаты (если задание выполнено), либо ждем его завершения. Затем мы включаем результат в общий ответ. Используя этот подход, вы можете уменьшить время отклика, что очень хорошо для ваших пользователей и рейтинга сайта.
Мы используем эту функцию для запуска одновременных операций. В одном из наших проектов у нас много пользовательских данных и много поставщиков услуг. Чтобы найти лучшего поставщика услуг, мы делаем тяжелые расчеты и проверки. Чтобы сделать это быстрее, мы создаем задачи для пользователя с каждым поставщиком услуг, запускаем их и собираем результаты, чтобы показать их пользователю. Это очень легко сделать с целевыми группами Celery.
from celery import group
@celery_app.task
def calculate_service_provider_task(user_id, provider_id):
user = User.objects.get(pk=user_id)
provider = ServiceProvider.objects.get(pk=provider_id)
return calculate_service_provider(user, provider)
@celery_app.task
def find_best_service_provider_for_user(user_id):
user = User.objects.get(pk=user_id)
providers = ServiceProvider.objects.related_to_user(user)
calc_group = group([
calculate_service_provider_task.s(user.pk, provider.pk)
for provider in providers
]).apply_async()
return calc_groupВо-первых, почему мы снова запускаем две задачи? Мы используем второе задание для формирования групп задач расчета, их запуска и возврата. Кроме того, вторая задача заключается в том, где вы можете назначить фильтрацию проекта - например, поставщиков услуг, которые необходимо рассчитать для данного пользователя. Все это можно сделать, пока Celery выполняет другую работу. Когда группа задач возвращается, результатом первой задачи является фактически интересующий нас расчет.
Вот пример того, как использовать этот подход в коде:
def view(request): find_job = find_best_service_provider_for_user.delay(request.user.pk) # do other stuff calculations_results = find_job.get().join() # process calculations_results and send response
Здесь мы выполняем вычисления как можно скорее, ожидаем результатов в конце метода, затем готовим ответ и отправляем его пользователю.
Полезные советы
Крошечные данные
Я, наверное, уже упоминал, что я использую идентификаторы записей базы данных в качестве аргументов задачи вместо полных объектов. Это хороший способ уменьшить размер очереди сообщений. Но что более важно, это то, что при выполнении задачи данные в базе данных могут быть изменены. И когда у вас есть только идентификаторы, вы получите свежие данные, а не устаревшие данные, которые вы получаете при передаче объектов.
Операции
Иногда могут возникнуть проблемы, когда выполненная задача не может найти объект в базе данных. Почему это происходит? Например, в Django вы хотите запускать задачи после регистрации пользователя, например отправку приветственного письма, а ваши настройки Django заключают все запросы в транзакцию. В Celery, однако, задачи выполняются быстро, еще до того, как транзакция будет завершена. Поэтому, если вы используете Celery при работе в Django, вы можете увидеть, что пользователь не существует в базе данных (пока).
вы можете использовать метод apply_async в задании, класс, который задает задачу в сигнале transaction.on_commit, а не выполняет ее немедленно.
Перевод статьи: Celery Python Guide: Basics and Examples
Источник: gitconnected.com