Давайте создадим сквозной конвейер веб-скрапинга с Scrapy!

Парсинг веб-страниц стал незаменимым инструментом для сбора данных, позволяющим разработчикам и энтузиастам данных получать доступ к ценной информации из Интернета. Такие инструменты, как BeautifulSoup4 и Selenium, — это удобные инструменты, которые максимально упрощают эту задачу, особенно для одноразовых сценариев и базовых рабочих процессов.
Однако парсинг веб-страниц часто является лишь первым шагом в более широком процессе извлечения, преобразования, загрузки (ETL). По мере роста ваших потребностей будет расти и количество пользовательских сценариев. Без структуры для организации этих одноразовых сценариев это неизбежно приведет к путанице в будущем.
Как однажды сказал Альберт Эйнштейн: «Все должно быть сделано как можно проще, но не проще». Вот тут-то и приходит на помощь Scrapy!
В этом уроке я собираюсь познакомить вас с процессом очистки веб-страниц ETL с использованием Scrapy, который собирает цитаты, такие как цитата Эйнштейна, и загружает их в базу данных SQLite. Мы будем использовать Quotes to Scrape в качестве целевого сайта для парсинга:
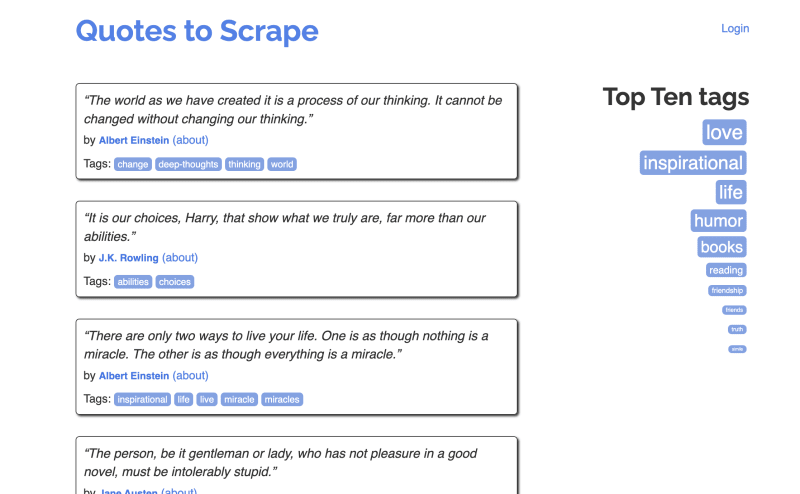
Мы рассмотрим следующее:
- Создание виртуальной среды для Python.
- Настройка Scrapy, фреймворка для очистки веб-страниц Python.
- Создание веб-парсера с использованием Scrapy для извлечения цитат с веб-сайта.
- Настройка конвейера Scrapy для обработки и хранения очищенных данных.
- Создание базы данных SQLite с использованием Python.
- Хранение очищенных данных в базе данных SQL
- (Для развлечения) Анализ очищенных данных с помощью Pandas и Matplotlib
Шаг 1. Создание виртуальной среды
Прежде чем мы углубимся, хорошей идеей будет создать чистую и изолированную среду Python с использованием виртуальной среды. Это гарантирует, что пакеты и зависимости вашего проекта Scrapy не будут мешать вашей общесистемной установке Python, и он автоматически перенаправит CLI Scrapy в PATH виртуальной среды для максимального удобства использования.
Вот шаги для создания виртуальной среды:
- Откройте терминал или командную строку на своем компьютере.
- Перейдите в каталог, в котором вы хотите создать проект Scrapy.
- Оказавшись в нужном каталоге, выполните следующую команду, чтобы создать виртуальную среду с именем
quotesenv(вы можете заменитьquotesenvна предпочитаемое вами имя):
python -m venv quotesenvПосле выполнения этой команды у вас появится новый каталог с именем myenv (или выбранное вами имя) в каталоге вашего проекта. Этот каталог содержит чистую среду Python, в которой вы можете устанавливать пакеты, не затрагивая общесистемную установку Python.
Теперь, когда у вас настроена виртуальная среда, вы можете перейти к следующему шагу: установке Scrapy и созданию проекта Scrapy.
Шаг 2. Установка Scrapy и создание вашего первого проекта
Пришло время установить Scrapy и создать проект Scrapy для нашей работы по парсингу веб-страниц.
- Активируйте свою виртуальную среду, если она еще не активирована. Вы можете сделать это, запустив:
source quotesenv/bin/activateЗамените quotesenv именем вашей виртуальной среды, если оно отличается
- Теперь вы можете установить Scrapy внутри своей виртуальной среды, используя
pip:
pip install scrapy- После установки Scrapy вы можете создать новый проект Scrapy, используя следующую команду:
scrapy startproject quotes\_projectЭта команда создаст структуру каталогов для вашего проекта Scrapy, включая все необходимые файлы и шаблон для начала работы:
\>quotes\_project/
scrapy.cfg
quotes\_project/
\_\_init\_\_.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
\_\_init\_\_.py
quotes\_spider.pyВот как они все работают вместе:
Scrapy.cfg: это файл конфигурации проекта Scrapy. Он содержит настройки и конфигурации для вашего проекта Scrapy.quotes_project(directory): это пакет Python для вашего проекта Scrapy.- init.py: это пустой файл Python, который делает каталог пакетом Python.
- items.py: здесь вы определяете структуру элементов, которые будут хранить очищенные данные. Вы создаете классы элементов с полями, соответствующими данным, которые вы хотите очистить.
- middlewares.py: этот файл используется для определения пользовательских компонентов промежуточного программного обеспечения для вашего проекта Scrapy. Промежуточное программное обеспечение может изменять запросы и ответы во время процесса очистки.
- Pipelines.py: Здесь вы можете определить конвейеры обработки данных для обработки и хранения очищенных данных. Вы можете реализовать такие действия, как хранение данных в базах данных, экспорт данных в файлы или выполнение дополнительной обработки.
- settings.py: это основной файл конфигурации вашего проекта Scrapy. Вы можете установить различные параметры, специфичные для проекта, включая пользовательский агент, параллелизм и многое другое.
- Spiders(каталог): Этот каталог содержит пауков, очищающих веб-страницы.
- init.py: это пустой файл Python, который делает каталог пакетом Python.
- quotes_spider.py: это пример файла паука, в котором вы определяете паука для сканирования и сбора данных с веб-сайтов. Вы создаете классы, наследуемые от
Scrapy.Spider, и определяете, как паук перемещается и извлекает данные с веб-страниц. Мы создадим наш первый вместе.
Эта структура папок и файлов обеспечивает четкую организацию вашего проекта Scrapy, разделяя конфигурацию, определения элементов, код паука и логику обработки данных.
Теперь, когда у вас установлен Scrapy и настроен ваш проект, давайте перейдем к определению паука для сбора цитат с веб-сайта. Оставайтесь с нами для шага 3!
Шаг 3. Создание класса элемента для нашей структуры данных
На этом этапе мы определим структуру элемента, который будет хранить очищенные данные. Scrapy использует Items для структурирования и хранения данных, которые вы извлекаете с веб-сайтов.
Откройте файл [items.py](http://items.py/) в каталоге вашего проекта Scrapy. Этот файл создается автоматически, когда вы создаете проект Scrapy с помощью команды Scrapy startproject.
В [items.py](http://items.py/) вы заметите, что CLI уже создал класс QuotesScraperItem, который наследуется от Scrapy.Item. Добавьте следующий код и удалите оператор pass, чтобы определить структуру QuotesScraperItem:
import scrapy
class QuotesScraperItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()Этот фрагмент кода определяет класс элемента с двумя полями: title и author. Вы также можете получить данные tags, но это выходит за рамки данного руководства. Эти поля соответствуют данным, которые мы собираем с веб-сайта.
Определив структуру элементов, мы готовы перейти к созданию SPIDER — класса, отвечающего за часть извлечения нашего конвейера ETL. Я проделал работу по проверке целевого веб-сайта и поиску селекторов для данных, которые мы также будем собирать.
Шаг 4. Определение Scrapy Spider для очистки котировок
Scrapy Spider — это класс, который содержит правила навигации и извлечения данных с веб-сайта.
Давайте начнем:
- Создайте новый файл с именем
quotes_spider.pyвнутри каталогаquotes_project/quotes_project/spiders. Здесь мы определим нашего SPIDER. - Отредактируйте
quotes_spider.pyи добавьте приведенный ниже код.
import scrapy
from quotes\_project.items import QuotesScraperItem #made in the previous step
class QuotesSpider(scrapy.Spider):
name = "quotes"
start\_urls = \[
'http://quotes.toscrape.com/page/1/',
\]
def parse(self, response):
for quote in response.css('div.quote'):
item = QuotesScraperItem()
item\['text'\] = ''.join(quote.css('span.text::text').get())
item\['author'\] = ''.join(quote.css('span small::text').get())
yield item
next\_page = response.css('li.next a::attr(href)').get()
if next\_page is not None:
yield response.follow(next\_page, self.parse)Этот код определяет паука Scrapy под названием «quotes», который запускается по указанному URL-адресу и очищает цитаты и их авторов. Он также продолжает делать это для каждой страницы, пока не останется больше страниц. Строковая функция «».join() необходима, потому что поле text вернет список строк, а не одну строку, и это позволяет нам легко объединить их.
Чтобы запустить паука и увидеть его в действии, используйте следующую команду в корневом каталоге вашего проекта:
scrapy crawl quotesТеперь ваш паук начнет собирать цитаты с сайта. Но вам некуда его положить… Не бойтесь, это будет дальше!
Шаг 5. Сохранение очищенных данных в базе данных SQLite
Теперь, когда вы успешно извлекли данные из Интернета, пришло время сохранить эти данные в базе данных для будущего использования и анализа. На этом этапе мы настроим базу данных SQLite в качестве места назначения для данных в нашем конвейере автоматически при запуске конвейера.
В Scrapy за обработку очищенных данных отвечают конвейеры. Мы создадим собственный конвейер для вставки очищенных элементов в только что созданную базу данных SQLite.
- В папке проекта Scrapy перейдите в каталог
quotes_scraper(или имя вашего проекта) и откройте файл[pipelines.py](http://pipelines.py/). - Определите следующий класс конвейера в конце файла.
import sqlite3
from itemadapter import ItemAdapter
class QuotesToSQLitePipeline:
def \_\_init\_\_(self):
self.conn = sqlite3.connect('quotes.db')
self.cursor = self.conn.cursor()
def process\_item(self, item, spider):
adapter = ItemAdapter(item)
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS quotes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT,
author TEXT
)
''')
self.cursor.execute('''
INSERT INTO quotes (text, author)
VALUES (?, ?)
''', (adapter\['text'\], adapter\['author'\]))
self.conn.commit()
return item
def close\_spider(self, spider):
self.conn.close()Этот класс конвейера создает (если он еще не существует) или подключается к базе данных SQLite, вставляет очищенные данные в таблицу котировок и закрывает соединение, когда паук завершает работу. ItemAdapter позволяет нам получать данные внутри Item без необходимости импортировать сам этот Item (менее тесно связанный, ура!).
Шаг 6. Включение конвейера
Чтобы включить свой собственный конвейер, добавьте его в файл [settings.py](http://settings.py/) в папке проекта Scrapy:
\# settings.py
\# ...
# Configure item pipelines
ITEM\_PIPELINES = {
'quotes\_scraper.pipelines.QuotesToSQLitePipeline': 300, # Adjust the priority if needed
}
# ...В этом примере я установил приоритет конвейера на 300, но вы можете настроить его по мере необходимости.
Шаг 7. Запуск вашего Spider и сохранение данных
Теперь, когда все настроено, вы можете снова запустить своего паука и посмотреть, как Scrapy сохраняет очищенные данные в базу данных SQLite:
scrapy crawl quotesScrapy запустит вашего паука и с помощью специального конвейера сохранит очищенные цитаты и авторов в базу данных quotes.db, которая теперь будет находиться в папке вашего проекта.
Вот и все, что касается Шага 4! Вы успешно настроили базу данных SQLite и настроили конвейер для сохранения очищенных данных. На следующих шагах мы рассмотрим, как извлекать и анализировать данные.
Шаг 8. Получение данных из базы данных SQLite
Вы успешно очистили и сохранили данные в базе данных SQLite с помощью Scrapy. На этом этапе мы рассмотрим, как получить эти данные из базы данных и выполнить базовые запросы.
Шаг 9. Подключение к базе данных
Чтобы получить данные из базы данных SQLite, нам нужно установить соединение и создать объект курсора, затем выполнить выбор и, наконец, напечатать то, что возвращается от курсора. Создайте файл с именем restart_quotes.py в корневой папке проекта и скопируйте в него следующее:
import sqlite3
def retrieve\_quotes():
# Create a context manager for the SQLite connection
with sqlite3.connect('quotes.db') as conn:
# Create a cursor within the context manager
cursor = conn.cursor
# Execute an SQL query to retrieve all quotes
cursor.execute('SELECT \* FROM quotes')
# Fetch all the results from the cursor; fetchall() function returns a list.
quotes = cursor.fetchall(
# Display the retrieved data
for quote in quotes:
print(quote)
if \_\_name\_\_ == "\_\_main\_\_": Шаг 2. Запуск сценария
Чтобы запустить скрипт и получить данные из базы данных, используйте следующую команду или запустите ее в своей IDE:
python retrieve\_data.pyСкрипт подключится к базе данных, получит данные и отобразит их в терминале.
Вот и все, что касается Шага 5! Вы узнали, как получать данные из базы данных SQLite, в которой вы сохранили очищенные цитаты и авторов. На следующих шагах мы углубимся в анализ и визуализацию данных.
Шаг 6: (для развлечения) Анализ и визуализация данных
На этом необязательном этапе вы можете дополнительно изучить собранные данные, выполнив анализ и визуализацию данных. Для этого мы будем использовать библиотеки Python, такие как Pandas и Matplotlib. Данных едва хватает, чтобы с ними заморачиваться, но я подумал, что было бы неплохо показать этот шаг для выполнения самого минимального из MVP для полного варианта использования конвейера Scrapy!
Шаг 1. Импорт необходимых библиотек
Сначала убедитесь, что у вас установлены необходимые библиотеки Python. Вы можете установить их с помощью pip:
pip install pandas matplotlibШаг 2: Анализ данных
Теперь давайте проведем базовый анализ собранных данных. Мы будем использовать Pandas для загрузки данных из базы данных SQLite в DataFrame, а затем посчитаем некоторую статистику. В корневой папке проекта создайте скрипт Python с именем data_anasis.py и добавьте следующий код. Это напечатает общее количество записей с использованием панд.
import pandas as pd
import sqlite3
\# Connect to the SQLite database
conn = sqlite3.connect('quotes.db')
\# Load data into a Pandas DataFrame
df = pd.read\_sql\_query('SELECT \* FROM quotes', conn)
\# Calculate the number of quotes
total\_quotes = len(df)
\# Display the total number of quotes
print(f'Total Number of Quotes: {total\_quotes}')Шаг 3: Визуализация данных
Далее давайте создадим простую гистограмму, чтобы визуализировать распределение цитат по авторам. Для этой цели мы будем использовать Matplotlib. Добавьте импорт в начало data_anasis.py и скопируйте все, начиная с тела приведенного ниже кода, до конца data_anasis.py:
import matplotlib.pyplot as plt
\# Group quotes by author and count the occurrences
author\_counts = df\['author'\].value\_counts()
\# Create a bar chart
plt.figure(figsize=(12, 6))
author\_counts.plot(kind='bar')
plt.title('Quotes by Author')
plt.xlabel('Author')
plt.ylabel('Number of Quotes')
plt.xticks(rotation=45)
plt.tight\_layout()
plt.show()Шаг 4. Запуск сценария
Запустите скрипт с помощью следующей команды:
python data\_analysis.pyПосле запуска скрипта вы увидите общее количество цитат, отображаемых в консоли, и появится гистограмма, показывающая распределение цитат по авторам.
На этом завершается шаг 6, на котором у вас есть возможность выполнить анализ и визуализацию собранных данных.
Подведение итогов и дальнейшие шаги
Поздравляем! Вы завершили мое руководство по процессу парсинга веб-страниц и извлечению данных с помощью Scrapy. На этом этапе у вас будет:
- Создана виртуальная среда для вашего проекта Python для управления зависимостями.
- Настройте проект Scrapy и определите паука для очистки веб-страниц.
- Извлекли цитаты и авторов с веб-сайта с помощью Scrapy.
- Создал базу данных SQLite и сохранил очищенные данные.
- Реализован Scrapy-конвейер для автоматизации хранения данных.
- Проведен анализ и визуализация собранных данных.
Следующие шаги
Теперь, когда у вас есть прочная основа в парсинге веб-страниц с помощью Scrapy, вы можете изучать более сложные темы и реальные приложения. В ближайшие недели я буду писать и давать ссылки на руководства, построенные на основе этого простого конвейера. Они охватят такие темы, как:
- Сбор данных с нескольких веб-сайтов и их объединение.
- Работа с различными форматами и структурами данных.
- Планирование выполнения задач веб-скрапинга через определенные промежутки времени.
- Реализация аутентификации пользователей для очистки страниц входа.
- Масштабируйте свои усилия по парсингу с помощью распределенных систем.
Не стесняйтесь применять знания и методы, которые вы изучили здесь, для сбора данных для своих проектов, исследований или задач анализа данных. Если после прочтения этой статьи вы сделаете что-то крутое из конвейера Scrapy, дайте мне знать! Я бы хотел это увидеть!
Собирайте ответственно и получайте удовольствие!