Пишите эффективный код на Python: определение и измерение эффективности кода
В качестве специалиста по данным, вы должны тратить большую часть своего времени на получение информации из данных, не дожидаясь завершения работы вашего кода. Написание эффективного кода Python может помочь сократить время выполнения и сэкономить вычислительные ресурсы, что в конечном итоге освободит вас для выполнения более важных задач.
В этой статье мы обсудим, что такое эффективный код Python и как использовать различные встроенные структуры данных, функции и модули Python для написания более чистого, быстрого и эффективного кода. Мы рассмотрим, как рассчитать время и профилировать код, чтобы найти узкие места. Затем в следующей статье мы попрактикуемся в устранении этих узких мест и других плохих шаблонов проектирования, используя библиотеки Python, наиболее часто используемые специалистами по данным: NumPy и pandas.
1. Определение эффективности
1.1. Что понимается под эффективным кодом?
Эффективный относится к коду, который удовлетворяет двум ключевым понятиям. Во-первых, эффективный код работает быстро и имеет небольшую задержку между выполнением и возвратом результата. Во-вторых, эффективный код умело распределяет ресурсы и не требует ненужных накладных расходов. Хотя в целом ваше определение быстрой среды выполнения и небольшого использования памяти может различаться в зависимости от поставленной задачи, цель написания эффективного кода по-прежнему состоит в том, чтобы уменьшить как задержку, так и накладные расходы.
Python — это язык, который гордится удобочитаемостью кода, поэтому у него есть собственный набор идиом и лучших практик. Написание кода Python в том виде, в котором он был задуман, часто называют кодом Pythonic. Это означает, что код, который вы пишете, соответствует лучшим практикам и руководящим принципам Python. Код Pythonic, как правило, менее многословен и его легче интерпретировать. Хотя Python поддерживает код, который не соответствует его руководящим принципам, этот тип кода имеет тенденцию работать медленнее.
В качестве примера посмотрите на не-Pythonic ниже. Этот код не только более многословен, чем версия Pythonic, но и требует больше времени для выполнения. Мы более подробно рассмотрим, почему это так, позже в ходе курса, но сейчас основной вывод здесь заключается в том, что код Pythonic является эффективным кодом.
# Non-Pythonic
doubled_numbers = []
for i in range(len(numbers)):
doubled_numbers.append(numbers[i] * 2)
# Pythonic
doubled_numbers = [x * 2 for x in numbers]1.2. Стандартные библиотеки Python
Стандартные библиотеки Python — это встроенные компоненты и библиотеки Python. Эти библиотеки поставляются с каждой установкой Python и обычно упоминаются как одна из самых сильных сторон Python. Python имеет ряд встроенных типов.
Стоит отметить, что встроенные модули Python были оптимизированы для работы с самим языком Python. Следовательно, мы должны по умолчанию использовать встроенное решение (если оно существует), а не разрабатывать собственное.
Мы сосредоточимся на некоторых встроенных типах, функциях и модулях. Типы, на которых мы сосредоточимся:
- Списки (Lists)
- Кортежи (Tuples)
- Наборы (Sets)
- Дикты (Dicts)
Встроенные функции, на которых мы сосредоточимся:
- print()
- len()
- range()
- round()
- enumerate()
- map()
- zip()
Наконец, встроенные модули, с которыми мы будем работать:
- os
- sys
- NumPy
- pandas
- itertools
- collections
- math
Функции Python
Давайте начнем изучать некоторые из упомянутых функций:
- range(): это удобный инструмент, когда мы хотим создать последовательность чисел. Предположим, мы хотим создать список целых чисел от нуля до десяти. Мы могли бы явно ввести каждое целое число, но это не очень эффективно. Вместо этого мы можем использовать диапазон для выполнения этой задачи. Мы можем указать диапазон с начальным и конечным значением для создания этой последовательности. Или мы можем указать только значение остановки, предполагая, что мы хотим, чтобы наша последовательность начиналась с нуля. Обратите внимание, что стоп-значение является эксклюзивным или до, но не включая это значение. Также обратите внимание, что функция диапазона возвращает объект диапазона, который мы можем преобразовать в список и распечатать. Функция диапазона также может принимать начальное, конечное и ступенчатое значение (в указанном порядке).
# range(start,stop)
nums = range(0,11)
nums_list = list(nums)
print(nums_list)
# range(stop)
nums = range(11)
nums_list = list(nums)
print(nums_list)
# Using range() with a step value
even_nums = range(2, 11, 2)
even_nums_list = list(even_nums)
print(even_nums_list)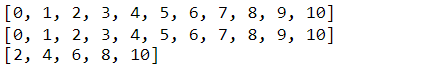
- enumerate(): еще одна полезная встроенная функция — enumerate. enumerate создает пару элементов индекса для каждого элемента предоставленного объекта. Например, вызов enumerate для букв списка создает последовательность индексированных значений. Подобно функции диапазона, enumerate возвращает объект перечисления, который также можно преобразовать в список и распечатать.
letters = ['a', 'b', 'c', 'd' ]
indexed_letters = enumerate(letters)
indexed_letters_list = list(indexed_letters)
print(indexed_letters_list)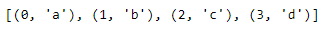
Мы также можем указать начальный индекс enumerate с ключевым словом start. Здесь мы указываем enumerate начинать индекс с пяти, передавая start equals Five в вызов функции.
#specify a start value
letters = ['a', 'b', 'c', 'd' ]
indexed_letters2 = enumerate(letters, start=5)
indexed_letters2_list = list(indexed_letters2)
print(indexed_letters2_list)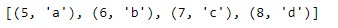
- map(): последняя известная встроенная функция, которую мы рассмотрим, — это функция map(). map применяет функцию к каждому элементу объекта. Обратите внимание, что функция map принимает два аргумента; во-первых, функция, которую вы хотите применить, а во-вторых, объект, к которому вы хотите применить эту функцию. Здесь мы используем карту, чтобы применить встроенную функцию round к каждому элементу списка nums.
nums = [1.5, 2.3, 3.4, 4.6, 5.0]
rnd_nums = map(round, nums)
print(list(rnd_nums))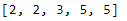
Функцию map также можно использовать с lambda или анонимной функцией. Обратите внимание, что мы можем использовать функцию map и lambda-выражение, чтобы применить функцию, которую мы определили на лету, к нашему исходному списку nums. Функция map обеспечивает быстрый и чистый способ итеративного применения функции к объекту без написания for loop.
# map() with lambda
nums = [1, 2, 3, 4, 5]
sqrd_nums = map(lambda x: x ** 2, nums)
print(list(sqrd_nums))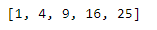
Модули Python
NumPy, или Numerical Python, — бесценный пакет Python для специалистов по данным. Это основной пакет для научных вычислений в Python, который предоставляет ряд преимуществ для написания эффективного кода.
Массивы NumPy представляют собой быструю и экономичную альтернативу спискам Python. Обычно мы импортируем NumPy как np и используем массив точек np для создания массива NumPy.
# python list
nums_list = list(range(5))
print(nums_list)
# using numpyu alternative to python lists
import numpy as np
nums_np = np.array(range(5))
print(nums_np)
Массивы NumPy являются гомогенными, а это значит, что они должны содержать элементы одного типа. Мы можем увидеть тип каждого элемента, используя метод .dtype. Предположим, мы создали массив, используя смесь типов. Здесь мы создаем массив nums_np_floats, используя целые числа [1,3] и число с плавающей запятой [2.5]. Можете ли вы заметить разницу в выходе? Целые числа теперь имеют начальную точку в массиве. Это связано с тем, что NumPy преобразовал целые числа в числа с плавающей запятой, чтобы сохранить однородный характер этого массива. Используя .dtype, мы можем убедиться, что элементы в этом массиве являются числами с плавающей запятой.
# NumPy array homogeneity
nums_np_ints = np.array([1, 2, 3])
print('integer numpy array',nums_np_ints)
print(nums_np_ints.dtype)
nums_np_floats = np.array([1, 2.5, 3])
print('float numpy array',nums_np_floats)
print(nums_np_floats.dtype)
Однородность позволяет массивам NumPy быть более эффективными с точки зрения памяти и быстрее, чем списки Python. Требование, чтобы все элементы были одного типа, устраняет накладные расходы, необходимые для проверки типа данных.
При анализе данных часто требуется быстро выполнять операции над целым набором значений. Скажем, например, вы хотите возвести в квадрат каждое число в списке чисел. Было бы неплохо, если бы мы могли просто возвести список в квадрат и получить список значений, возведенных в квадрат. К сожалению, списки Python не поддерживают такие типы вычислений.
# Python lists don't support broadcasting
nums = [-2, -1, 0, 1, 2]
nums ** 2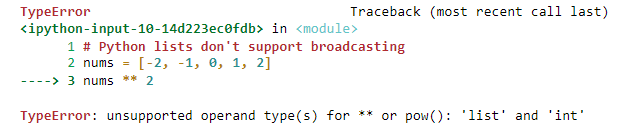
Мы могли бы возвести в квадрат значения, используя список, написав for loop или используя понимание списка, как показано в коде ниже. Но ни один из этих подходов не является наиболее эффективным способом сделать это. Здесь кроется второе преимущество массивов NumPy — их широковещательная функциональность. Массивы NumPy векторизуют операции, поэтому они выполняются сразу над всеми элементами объекта. Это позволяет нам эффективно выполнять вычисления над целыми массивами. Давайте сравним время вычислений с использованием этих трех подходов в следующем коде:
import time
# define numerical list
nums = range(0,1000)
nums = list(nums)
# For loop (inefficient option)
# get the start time
st = time.time()
sqrd_nums = []
for num in nums:
sqrd_nums.append(num ** 2)
#print(sqrd_nums)
# get the end time
et = time.time()
# get the execution time
elapsed_time = et - st
print('Execution time using for loops over list:', elapsed_time, 'seconds')
# List comprehension (better option but not best)
# get the start time
st = time.time()
sqrd_nums = [num ** 2 for num in nums]
#print(sqrd_nums)
# get the end time
et = time.time()
print('Execution time using list comprehension:', elapsed_time, 'seconds')
# using numpy array broadcasting
# define the numpy array
nums_np = np.arange(0,1000)
# get the start time
st = time.time()
nums_np ** 2
# get the end time
et = time.time()
# get the execution time
elapsed_time = et - st
print('Execution time using numpy array broadcasting:', elapsed_time, 'seconds')
Мы видим, что первые два подхода имеют одинаковую временную сложность, в то время как использование NumPy в третьем подходе сократило время вычислений вдвое.
Еще одним преимуществом массивов NumPy являются их возможности индексации. При сравнении базовой индексации между одномерным массивом и списком возможности идентичны. При использовании двумерных массивов и списков преимущества массивов очевидны. Чтобы вернуть второй элемент первой строки в нашем двумерном объекте, используется синтаксис массива [0,1]. Синтаксис аналогичного списка немного более подробный, так как вам нужно заключить и ноль, и единицу в квадратные скобки [0][1]. Чтобы вернуть значения первого столбца в двумерном объекте, используется синтаксис массива [:,0]. Списки не поддерживают этот тип синтаксиса, поэтому мы должны использовать понимание списка для возврата столбцов.
#2-D list
nums2 = [ [1, 2, 3],
[4, 5, 6] ]
# 2-D array
nums2_np = np.array(nums2)
# printing the second item of the first row
print(nums2[0][1])
print(nums2_np[0,1])
# printing the first row values
print([row[0] for row in nums2])
print(nums2_np[:,0])
Массивы NumPy также имеют специальную технику, называемую булевым индексированием. Предположим, мы хотим собрать только положительные числа из приведенной здесь последовательности. С массивом мы можем создать логическую маску, используя простое неравенство. Индексировать массив так же просто, как заключить это неравенство в квадратные скобки. Однако, чтобы сделать это с помощью списка, нам нужно написать for loop для фильтрации списка или использовать понимание списка. В любом случае использование массива NumPy для индекса менее подробно и имеет более быстрое время выполнения.
nums = [-2, -1, 0, 1, 2]
nums_np = np.array(nums)
# Boolean indexing
print(nums_np[nums_np > 0])
# No boolean indexing for lists
# For loop (inefficient option)
pos = []
for num in nums:
if num > 0:
pos.append(num)
print(pos)
# List comprehension (better option but not best)
pos = [num for num in nums if num > 0]
print(pos)2. Синхронизация и профилирование кода Python
Во втором разделе статьи вы узнаете, как собирать и сравнивать время выполнения для разных подходов к кодированию. Вы попрактикуетесь в использовании пакетов line_profiler и memory_profiler для профилирования базы кода и выявления узких мест. Затем вы примените полученные знания на практике, заменив эти узкие места эффективным кодом Python.
2.1. Исследование времени выполнения Python
Как упоминалось в предыдущем разделе, код эффективности кода означает быстрый код. Чтобы иметь возможность измерить, насколько быстр наш код, нам нужно иметь возможность измерять время выполнения кода. Сравнение времени выполнения между двумя базами кода, которые эффективно делают одно и то же, позволяет нам выбрать код с оптимальной производительностью. Собирая и анализируя время выполнения, мы можем быть уверены, что реализуем самый быстрый и, следовательно, более эффективный код.
Чтобы сравнить время выполнения, нам нужно иметь возможность вычислить время выполнения для строки или нескольких строк кода. IPython поставляется с несколькими удобными встроенными волшебными командами, которые мы можем использовать для синхронизации нашего кода. Волшебные команды — это усовершенствования, добавленные поверх обычного синтаксиса Python. Эти команды имеют префикс со знаком процента.
Давайте начнем с этого примера: мы хотим проверить среду выполнения на предмет выбора 1000 случайных чисел от нуля до единицы с помощью функции NumPy random.rand(). Использование %timeit просто требует добавления волшебной команды перед строкой кода, которую мы хотим проанализировать. Одна простая команда для сбора времени выполнения.
%timeit rand_nums = np.random.rand(1000)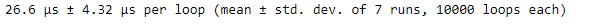
Как мы видим, %timeit предоставляет среднее значение статистики времени. Это одно из преимуществ использования %timeit. Мы также видим, что было создано несколько прогонов и циклов. %timeit выполняет предоставленный код несколько раз, чтобы оценить среднее время выполнения кода. Это обеспечивает более точное представление фактического времени выполнения вместо того, чтобы полагаться только на одну итерацию для расчета времени выполнения. Среднее значение и стандартное отклонение, отображаемые в выходных данных, представляют собой сводку времени выполнения с учетом каждого из нескольких запусков.
Количество запусков показывает, сколько итераций вы хотели бы использовать для оценки времени выполнения. Количество циклов показывает, сколько раз вы хотите, чтобы код выполнялся за одно прогон. Мы можем указать количество прогонов, используя -r flag, и количество циклов, используя -n flag. Здесь мы используем -r2, чтобы установить количество циклов равным двум, и -n10, чтобы установить количество циклов равным десяти. В этом примере %timeit выполнит наш выбор случайных чисел 20 раз, чтобы оценить время выполнения (2 запуска по 10 выполнений в каждом).
# Set number of runs to 2 (-r2)
# Set number of loops to 10 (-n10)
%timeit -r2 -n10 rand_nums = np.random.rand(1000)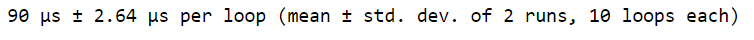
Еще одна интересная особенность %timeit — возможность запускать одну или несколько строк кода. При использовании %timeit в режиме магии строк или с одной строкой кода используется один знак процента, и мы можем запустить %timeit в режиме магии ячеек (или указать несколько строк кода), используя два знака процента.
%%timeit
# Multiple lines of code
nums = []
for x in range(10):
nums.append(x)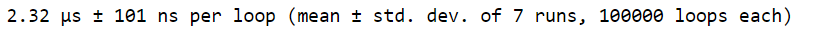
Мы также можем сохранить вывод %timeit в переменную, используя -o flag. Это позволяет нам глубже изучить выходные данные и увидеть такие вещи, как время для каждого запуска, лучшее время для всех запусков и худшее время для всех запусков.
# Saving the output to a variable and exploring them
times = %timeit -o rand_nums = np.random.rand(1000)
print('The timings for all the 7 runs',times.timings)
print('The best timing is',times.best)
print('The worst timeing is',times.worst)
2.2. Профилирование кода во время выполнения
Мы рассмотрели, как синхронизировать код с помощью волшебной команды %timeit, которая хорошо работает с небольшим кодом. Но что, если мы хотим замерить время большой базы кода или увидеть построчное время выполнения внутри функции? В этом разделе мы рассмотрим концепцию, называемую профилированием кода, которая позволяет более эффективно анализировать код.
Профилирование кода — это метод, используемый для описания того, как долго и как часто выполняются различные части программы. Прелесть профилировщика кода заключается в его способности собирать сводную статистику по отдельным частям нашего кода без использования магических команд, таких как %timeit. Мы сосредоточимся на пакете line_profiler для построчного профилирования времени выполнения функции. Поскольку этот пакет не является частью стандартной библиотеки Python, нам необходимо установить его отдельно. Это можно легко сделать с помощью команды pip install, как показано в коде ниже.
!pip install line_profilerДавайте рассмотрим использование line_profiler на примере. Предположим, у нас есть список имен, а также чей-то рост (в сантиметрах) и вес (в килограммах), загруженный в виде массивов NumPy.
names = ['Ahmed', 'Mohammed', 'Youssef']
hts = np.array([188.0, 191.0, 185.0])
wts = np.array([ 95.0, 100.0, 75.0])Затем мы разработаем функцию convert_units, которая преобразует рост каждого человека из сантиметров в дюймы и вес из килограммов в фунты.
def convert_units(names, heights, weights):
new_hts = [ht * 0.39370 for ht in heights]
new_wts = [wt * 2.20462 for wt in weights]
data = {}
for i,name in enumerate(names):
data[name] = (new_hts[i], new_wts[i])
return data
convert_units(names, hts, wts)
Если бы мы хотели получить примерное время выполнения этой функции, мы могли бы использовать %timeit. Но это даст нам только общее время выполнения. Что, если бы мы захотели узнать, сколько времени потребовалось для выполнения каждой строки внутри функции? Одним из решений является использование %timeit в каждой отдельной строке нашей функции convert_units. Но это много ручной работы и не очень эффективно.
%timeit convert_units(names, hts, wts)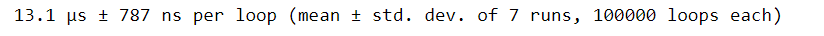
Вместо этого мы можем профилировать нашу функцию с помощью пакета line_profiler. Чтобы использовать этот пакет, нам сначала нужно загрузить его в нашем сеансе. Мы можем сделать это с помощью команды %load_ext, за которой следует line_profiler.
%load_ext line_profilerТеперь мы можем использовать волшебную команду %lprun из line_profiler, чтобы собрать время выполнения для отдельных строк кода в функции convert_units. %lprun использует специальный синтаксис. Во-первых, мы используем -f flag, чтобы указать, что мы хотим профилировать функцию. Затем мы указываем имя функции, которую хотим профилировать. Обратите внимание, имя функции передается без скобок. Наконец, мы предоставляем точный вызов функции, которую мы хотели бы профилировать, включая любые необходимые аргументы. Это показано в коде ниже:
%lprun -f convert_units convert_units(names, hts, wts)Вывод %lprun представляет собой удобную таблицу, в которой обобщаются статистические данные профилирования, как показано ниже. Первый столбец (называемый Line) указывает номер строки, за которым следует столбец, отображающий количество выполнений этой строки (называемый столбцом Hits). Затем в столбце «Time» показано общее время, затраченное на выполнение каждой строки. В этом столбце используется конкретный таймер, который можно найти в первой строке вывода. Здесь единица измерения таймера указана в 0,1 микросекунды, используя научную нотацию. Мы видим, что для выполнения второй строки потребовалось 362 единицы таймера, или примерно 36,2 микросекунды. Столбец Per Hit показывает среднее время, затрачиваемое на выполнение одной строки. Это рассчитывается путем деления столбца «Time» на столбец «Hits». Обратите внимание, что строка 6 выполнялась три раза и имела общее время выполнения 15,4 микросекунды, по 5 микросекунд на одно обращение. Столбец «% Time» показывает процент времени, затраченного на строку, по отношению к общему количеству времени, проведенному в функции. Это может быть хорошим способом увидеть, какие строки кода занимают больше всего времени внутри функции. Наконец, исходный код отображается для каждой строки в столбце «Line Contents».
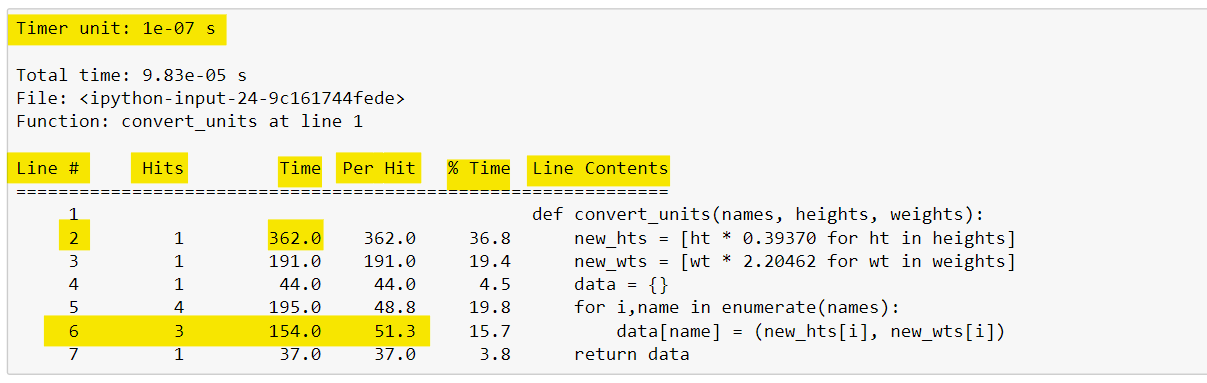
Следует отметить, что общее время, сообщаемое при использовании %lprun, и время, сообщаемое при использовании %timeit, не совпадают. Помните, что %timeit использует несколько циклов для вычисления среднего значения и стандартного отклонения времени, поэтому не ожидается, что время, сообщаемое каждой из этих волшебных команд, будет точно совпадать.
2.3. Профилирование кода для использования памяти
Мы определили эффективный код как код с минимальным временем выполнения и небольшим объемом памяти. До сих пор мы рассмотрели только то, как проверять время выполнения нашего кода. В этом разделе мы рассмотрим несколько методов оценки использования памяти нашим кодом.
Одним из основных подходов к проверке потребления памяти является использование встроенного в Python модуля sys. Этот модуль содержит системные функции и содержит один хороший метод .getsizeof, который возвращает размер объекта в байтах. sys.getsizeof() — это быстрый способ увидеть размер объекта.
import sys
nums_list = [*range(1000)]
sys.getsizeof(nums_list)
nums_np = np.array(range(1000))
sys.getsizeof(nums_np)
Мы видим, что выделение памяти для списка почти вдвое больше, чем для массива NumPy. Однако этот метод дает нам только размер отдельного объекта. Однако, если мы хотим проверить построчный размер памяти нашего кода. В качестве профиля времени выполнения мы могли бы использовать профилировщик кода. Точно так же, как мы использовали профилирование кода для сбора подробной статистики во время выполнения, мы также можем использовать профилирование кода для анализа выделения памяти для каждой строки кода в нашей кодовой базе. Мы будем использовать пакет memory_profiler, который очень похож на пакет line_profiler. Его можно загрузить через pip, и он поставляется с удобной волшебной командой (%mprun), которая использует тот же синтаксис, что и %lprun.
!pip install memory_profilerЧтобы иметь возможность применить %mprun к функции и вычислить выделение памяти, эта функция должна быть загружена из отдельного физического файла, а не из консоли IPython, поэтому сначала мы создадим файл utils_funcs.py и определим в нем функцию convert_units, а затем мы загрузим эту функцию из файла и применим к ней %mprun.
from utils_funcs import convert_units
%load_ext memory_profiler
%mprun -f convert_units convert_units(names, hts, wts)Вывод %mprun аналогичен выводу %lprun. На рисунке ниже мы можем увидеть построчное описание потребления памяти рассматриваемой функцией. Первый столбец представляет собой номер строки кода, который был профилирован. Второй столбец (использование памяти) — это память, используемая после выполнения этой строки. Далее столбец Increment показывает разницу в памяти текущей строки по отношению к предыдущей. Это показывает нам влияние текущей строки на общее использование памяти. Затем столбец вхождений определяет количество вхождений этой строки. В последнем столбце (Содержимое строки) показан профилированный исходный код.
Профилирование функции с помощью %mprun позволяет нам увидеть, какие строки занимают большой объем памяти, и, возможно, разработать более эффективное решение.
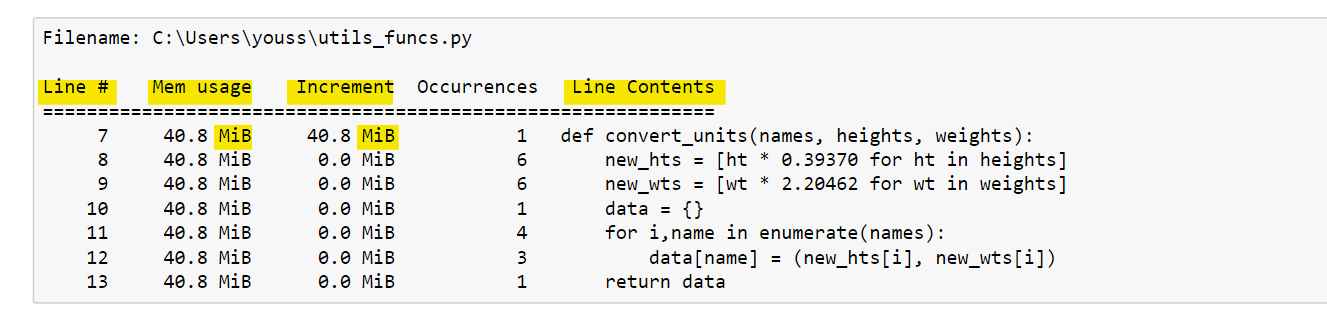
Важное замечание
Следует отметить, что память указывается в мегабайтах. Хотя один мегабайт не совсем совпадает с одним мегабайтом, для наших целей мы можем предположить, что они достаточно близки, чтобы означать одно и то же. Еще стоит отметить, что пакет memory_profiler проверяет потребление памяти, опрашивая операционную систему. Это может немного отличаться от объема памяти, фактически используемого интерпретатором Python. Таким образом, результаты могут различаться между платформами и даже между запусками. Несмотря на это, важную информацию все еще можно наблюдать.
В этой статье мы обсудили, что такое эффективный код Python, а затем обсудили и изучили некоторые из наиболее важных встроенных стандартных библиотек Python. После этого мы обсудили, как измерить эффективность вашего кода. В следующей статье мы обсудим, как оптимизировать ваш код на основе измерения эффективности, которое мы обсуждали в этой статье.