Топ-3 альтернативных пакета Python для Pandas

Для многих современных специалистов по обработке данных Python - это язык программирования, который использовался в повседневной работе - как следствие, анализ данных будет выполняться с использованием одного из самых распространенных пакетов данных, которым являются Pandas. Многие онлайн-курсы и лекции представят Pandas как основу для любого анализа данных с помощью Python.
На мой взгляд, Pandas по-прежнему остается наиболее полезным и жизнеспособным пакетом для анализа данных на Python. Однако для сравнения я хочу познакомить вас с несколькими альтернативами пакетов Pandas. Я не собираюсь убеждать людей переходить с Pandas на другой пакет, но я просто хочу, чтобы люди знали, что есть альтернативы для пакета Pandas.
Итак, что это за альтернативные пакеты Pandas? Давайте займемся этим!
Анализ кибербезопасности - Руководство для начинающих по обработке журналов безопасности в Python
Сегодняшний взаимосвязанный мир делает нас более уязвимыми для кибератак: вездесущие устройства Интернета вещей записывают и слушают то, что мы делаем, спам и фишинговые электронные письма угрожают нам каждый день, а атаки на сети, которые воруют данные, могут привести к серьезным последствиям. Эти системы создают терабайты журналов, полных информации, которая может помочь обнаружить и защитить уязвимые системы. По консервативным оценкам, компания среднего размера с сотнями и тысячами взаимосвязанных устройств может создавать до 100 ГБ файлов журналов в день. Кроме того, частота регистрируемых событий может достигать уровней, исчисляемых десятками тысяч в секунду.
CLX (выраженные клики) является частью экосистемы RAPIDS, которая ускоряет обработку и анализ киберлогов. Как часть RAPIDS, он построен на основе RAPIDS DataFrames cuDF и дополнительно расширяет возможности библиотеки RAPIDS ML cuML, используя последние достижения в области обработки естественного языка для организации неструктурированных данных и построения моделей классификации.
Системы машинного обучения и рекомендаций с использованием ваших собственных данных Spotify

Как человек, который ежедневно использует Spotify, мне было интересно, какой анализ я могу сделать с моими собственными музыкальными данными. Spotify отлично справляется с рекомендациями треков как через ежедневные миксы, так и через радиостанции, но как мы сами создадим что-то подобное? Целью здесь было использовать машинное обучение и методы системы рекомендаций, чтобы рекомендовать новые треки на основе треков из моих любимых плейлистов.
Генерация синтетических данных с помощью Numpy и Scikit-Learn

В этом руководстве мы обсудим детали создания различных синтетических наборов данных с использованием библиотек Numpy и Scikit-learn. Мы увидим, как можно сгенерировать разные образцы из разных распределений с известными параметрами.
Мы также обсудим создание наборов данных для различных целей, таких как регрессия, классификация и кластеризация. В конце мы увидим, как мы можем создать набор данных, имитирующий распределение существующего набора данных.
5 бесплатных и забавных API-интерфейсов для обучения, личных проектов и многого другого!

Публичные API - это круто!
4 лучших предварительно подготовленных модели для классификации изображений с помощью кода Python
Человеческий мозг может легко распознавать и различать объекты на изображении. Например, имея изображение кошки и собаки, за наносекунды мы различаем их, и наш мозг воспринимает это различие. Если машина имитирует это поведение, она максимально приближена к искусственному интеллекту. Впоследствии область компьютерного зрения направлена на имитацию системы зрения человека - и было много вех, которые преодолели барьеры в этом отношении.Более того, в наши дни машины могут легко различать разные изображения, обнаруживать предметы и лица и даже генерировать изображения людей, которых не существует! Очаровательно, не правда ли? Одним из моих первых опытов, когда я начинал работать с компьютерным зрением, была задача классификации изображений. Сама способность машины различать объекты ведет к большему количеству направлений исследований, например, к различению людей.

Создавайте красивые и интерактивные диаграммы аккордов с помощью Python
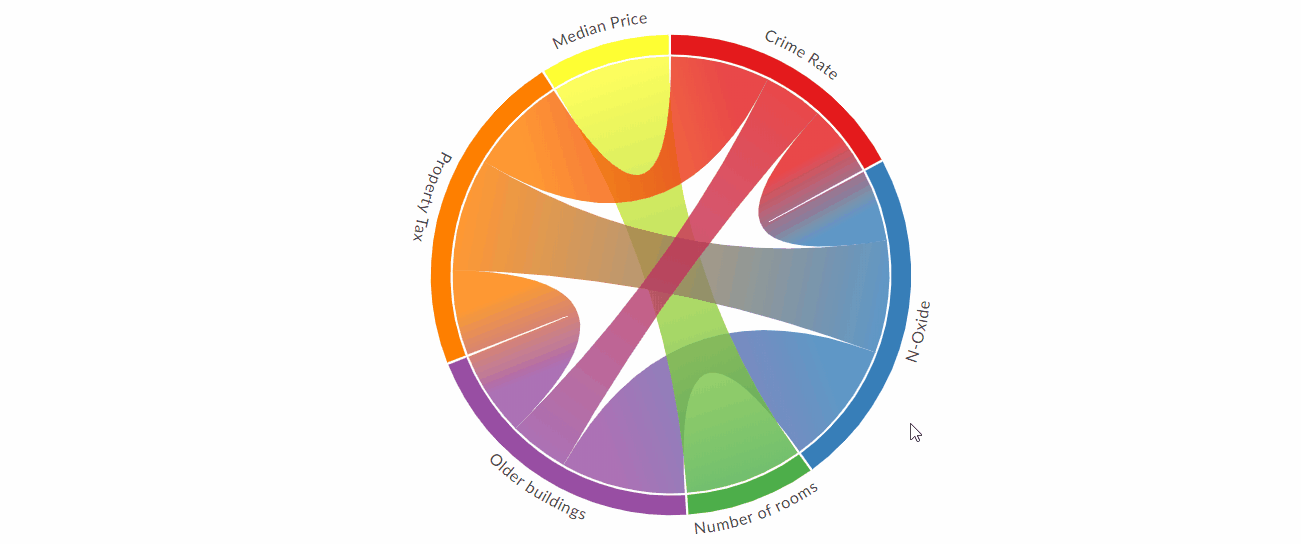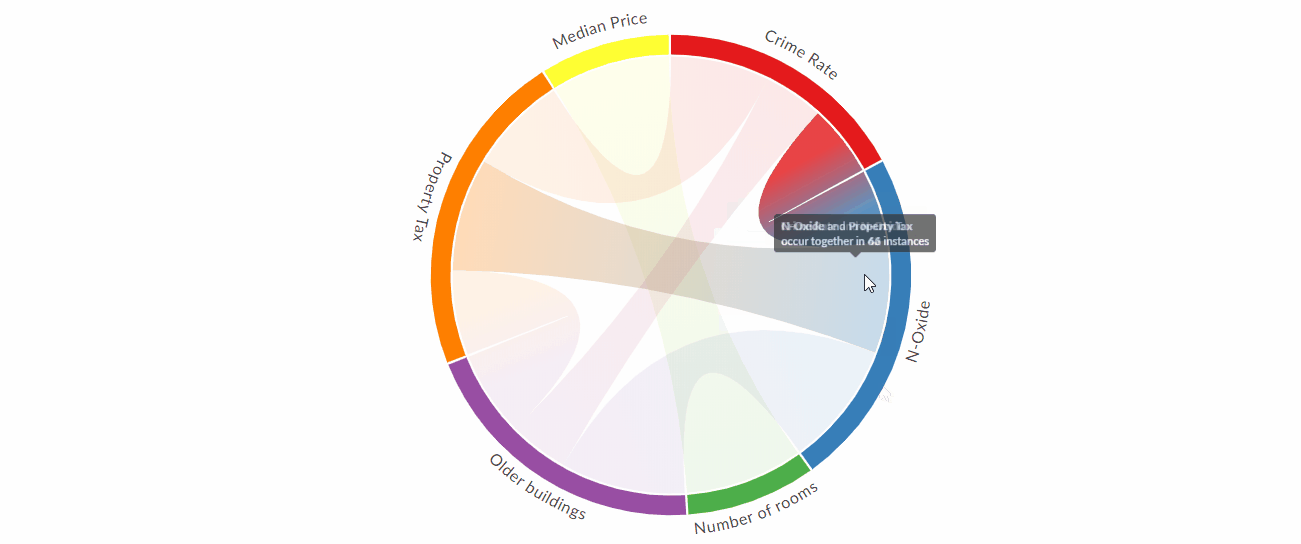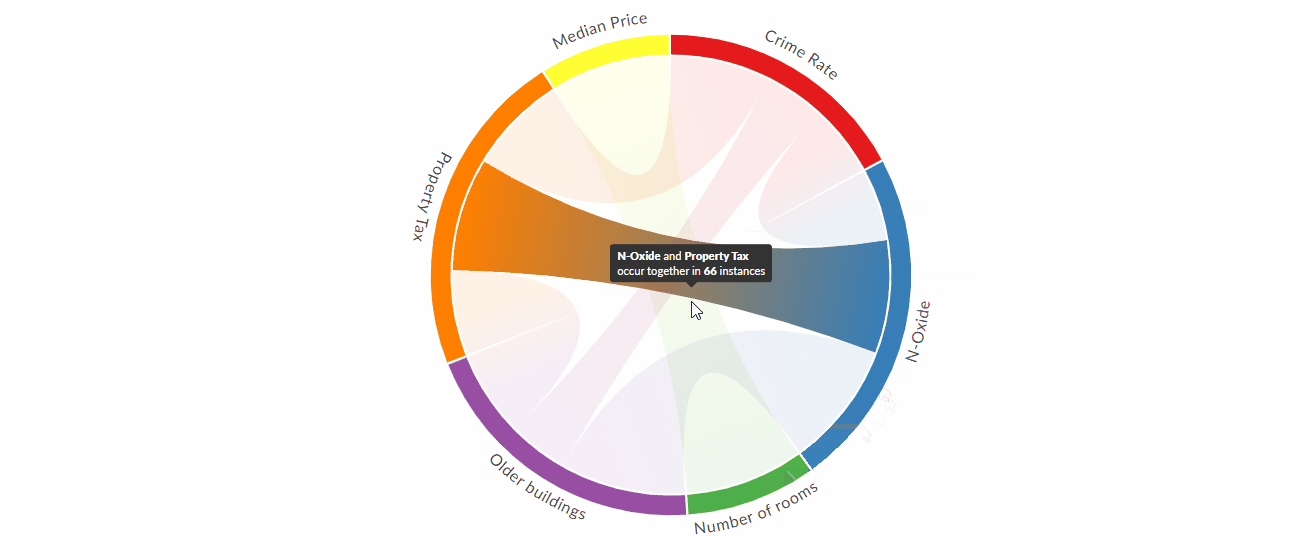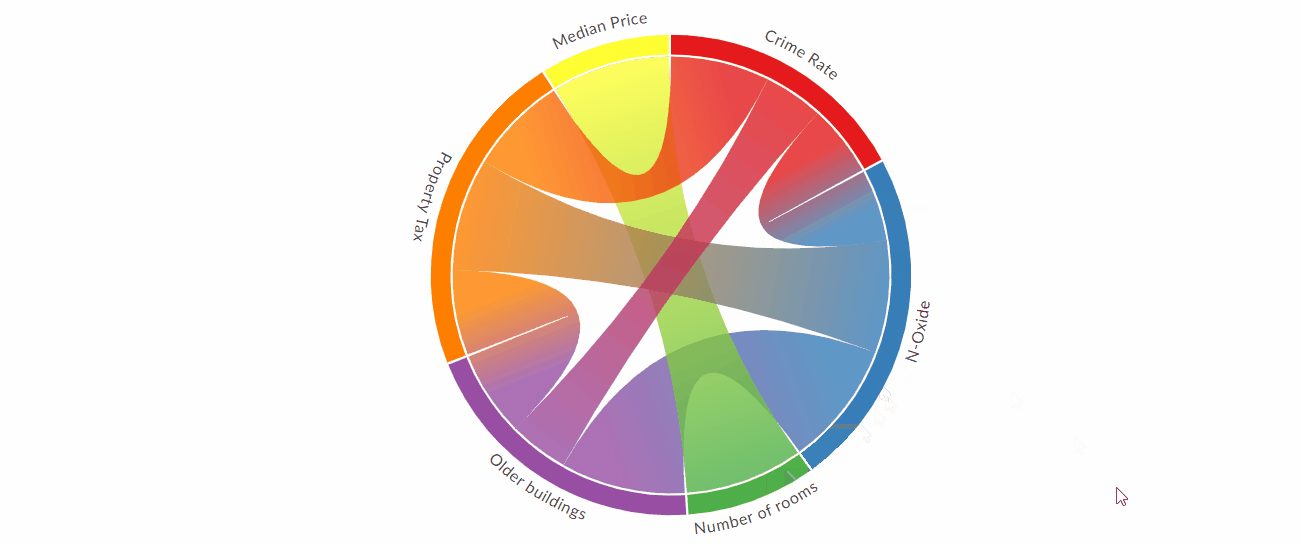
По мнению специалистов по данным, R против Python - это постоянная борьба, когда речь заходит о том, какой язык лучше. Хотя у каждого языка есть свои сильные стороны, на мой взгляд, у R есть один передовой трюк, который трудно превзойти: R имеет фантастические инструменты для передачи результатов посредством визуализации.
Надежная проверка 2 DataFrames с помощью Pandas 1.1.0

Pandas - одна из наиболее часто используемых библиотек Python как для специалистов по данным, так и для инженеров. Сегодня я хочу поделиться некоторыми советами по Python, которые помогут нам проводить проверки квалификации между двумя фреймами данных.
Интерактивная визуализация гео данных на Python
Гео данные могут быть интересными. Одна интерактивная геопространственная визуализация предоставляет много информации о данных и области и многое другое. У Python так много библиотек. Трудно понять, какой из них использовать. Для геопространственной визуализации я буду использовать Folium. Он очень прост в использовании, и он также имеет несколько стилей, чтобы соответствовать вашему выбору и требованиям.
Как использовать Python и Xpath для поиска данных в html

Платформы онлайн-обучения и соревнований по Kaggle обычно предоставляют вам полный (и чистый) набор данных. На практике, первый шаг проекта машинного обучения - получить в свои руки необходимые данные. Очистка веб-страниц или извлечение данных с веб-сайтов является одним из инструментов для достижения этой цели.
Присоединяйся в тусовку
Поделитесь своим опытом, расскажите о новом инструменте, библиотеке или фреймворке. Для этого не обязательно становится постоянным автором.